Tableaux et dimensions
Limites du tableau à 1 dimension
Utiliser un tableau est déjà une grande avancée pour regrouper des valeurs qui ont un lien et qui peuvent être traitées par lot. Malheureusement, nous allons rencontrer des cas qu’il est difficile de représenter avec un tableau simple.
Exemple :
Imaginons que nous voulions stocker les distances en kilomètres qui séparent des villes. Nous pourrions très facilement représenter ces distances sous forme de grille dans un tableur.
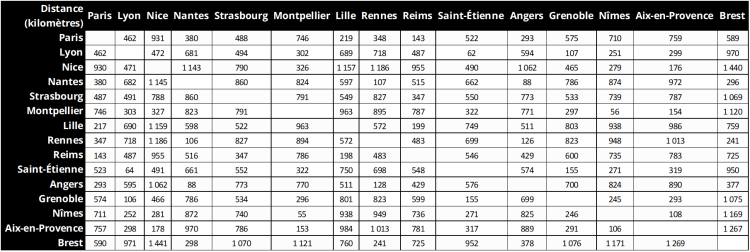
La difficulté ici est que pour retrouver une distance, il nous faut deux informations : la ville de départ et la ville d’arrivée. C’est exactement le même principe que sur une grille de bataille navale. Une case est identifiée à la fois par sa colonne et par sa ligne. D’ailleurs, notre tableur référence également les lignes avec des nombres et les colonnes avec des lettres, ce qui nous permet rapidement de savoir ce qu’il y a dans la case D26.
Si nous essayons de rapprocher cette grille du fonctionnement d’un tableau, nous aimerions mettre en place un tableau qui, au lieu d’accéder à un élément par un indice permettrait d’accéder à un élément à l’aide de deux indices : un pour la ligne et un pour la colonne. C’est ce que va nous permettre de faire un tableau à 2 dimensions. Mais avant d’en expliquer les propriétés, nous allons le construire pas à pas, en fonction de ce que nous connaissons déjà.
Exemple :
Prenons une grille de distances un peu plus simple.
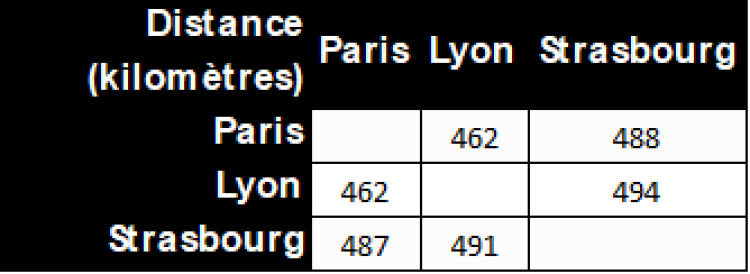
Nous savons utiliser les tableaux, déclarons donc 3 tableaux, 1 pour chaque ville, ainsi que des variables entières représentant les positions des villes dans le tableau (Paris : 0, Lyon : 1, Strasbourg : 2).
Variables :
Dist_Paris : entier[] = [0, 462, 488]
Dist_Lyon : entier[] = [462, 0, 494]
Dist_Strasbourg : entier[] = [487, 491, 0]
Ind_paris : entier = 0
Ind_lyon : entier = 1
Ind_strasbourg : entier = 2
Début
…
Fin
Remarque :
Avec ces quelques variables, je peux déjà résoudre mon problème de distance. Si je pars de Paris, il me suffit de prendre le tableau « dist_Paris ». Imaginons que je veuille récupérer la distance Paris → Strasbourg, je vais donc chercher dist_Paris[ind_strasbourg] (donc dist_Paris[2]),ce qui me retourne 488 km. En effet, le tableau dist_paris contient 3 valeurs :
Indice 0 : 0 km - distance Paris Paris
Indice 1 : 462 km - distance Paris Lyon
Indice 2 : 488 km - distance Paris Strasbourg
J’arrive donc bien, avec cette méthode, à récupérer la distance que je cherche en prenant le tableau correspondant à la ville de départ et l’indice qui correspond à la ville d’arrivée. Cependant, cette méthode me fait déclarer autant de tableaux que je gère de villes, la France possédant plus de 36 000 communes, je ne peux pas utiliser ce principe à grande échelle.
Tableaux à plusieurs dimensions
Rappel :
Nous avons vu que les tableaux pouvaient contenir plusieurs éléments de types simples (entier, réel, booléen, caractères). Imaginons maintenant qu’un tableau puisse contenir plusieurs éléments qui sont eux-mêmes des tableaux. Pour le comprendre, reprenons notre exemple de distance et faisons-le évoluer encore un peu. Dans mon exemple précédent, j’avais déclaré 3 tableaux :
Dist_Paris : entier[ ] = [0, 462, 488]
Dist_Lyon : entier[ ] = [462, 0, 494]
Dist_Strasbourg : entier[ ] = [487, 491, 0]
Rappel :
À partir de ces 3 tableaux, je vais déclarer un tableau qui va contenir 3 éléments : dist_Paris, dist_Lyon et dist_Strasbourg :
Dist : entier[][] = [dist_paris, dist_Lyon, dist_strasbourg]
Dist est de type entier[][], c’est un tableau de tableau d’entiers. En effet, dist_Paris, dist_Lyon et dist_Strasbourg sont des tableaux d’entiers. Si je remplace les variables dist par leurs valeurs, j’obtiens : Dist : entier[][] = [[0, 462, 488], [462, 0, 494], [487, 491, 0]].
Rappel :
Je viens ici de déclarer un tableau à 2 dimensions qui n’est rien d’autre qu’un tableau dont chaque élément est lui-même un tableau. Si on reprend ce que nous savons déjà sur les tableaux et les indices, nous pouvons donc dire que :
Dist[0] est le premier élément du tableau : [0, 462, 488],
Dist[1] est le second élément du tableau : [462, 0, 494],
Dist[2] est le troisième élément du tableau : [487, 491, 0].
Et donc la distance qui sépare Paris de Strasbourg est donc le 3ième élément du premier élément de dist : Dist[0][2] est le troisième élément de [0, 462, 488] soit 488.
Et si nous utilisons les indices suivants :
Ind_paris : entier = 0
Ind_lyon : entier = 1
Ind_strasbourg : entier = 2
Alors :
Dist[Ind_paris ][Ind_strasbourg] est le troisième élément de [0, 462, 488] soit 488.
Nous avons donc bien fabriqué un tableau qui nous permet de rechercher un élément à partir de deux indices (ici, indice de la ville de départ et indice de la ville d’arrivée). Ce tableau à deux dimensions va nous servir à chaque fois que nous aurons à représenter une grille, une carte ou un plateau de jeu. Il n’y a aucune limite dans le nombre de dimensions que l’on peut mettre en place dans la déclaration d’un tableau.
Plusieurs dimensions en mémoire
Fondamental :
On peut penser que la représentation mémoire d’un tableau à plusieurs dimensions peut être assez complexe mais elle suit les règles que nous avons vues jusqu’ici. En termes d’espace mémoire, la taille d’un tableau à 2 dimensions est facilement calculable. Si nous cherchons combien il y a d’éléments dans un tableau de n lignes sur k colonnes, nous nous rendons rapidement compte qu’il y en a n x k. La première chose que fait un programme pour stocker un tableau à deux dimensions, c’est déterminer de combien d’éléments il est constitué.
Méthode :
Si je reprends l’exemple des distances entre les villes et du tableau des distances que j’ai déclaré :
Variables :
Dist : entier[ ][ ] = [[0, 462, 488], [462, 0, 494], [487, 491, 0]]
Dist est un tableau de 3 lignes sur 3 colonnes, il s’agit donc d’un tableau qui contient 3 x 3 = 9 éléments entiers. Le programme va donc réserver 9 emplacements contigus en mémoire. Ensuite, il va stocker le premier élément qui est [0, 462, 488]. Stocker un tableau dans une variable, nous savons le faire, il suffit de stocker chacun des 3 éléments dans les zones mémoires disponibles. Et nous procédons de même pour tous les éléments du tableau dist :
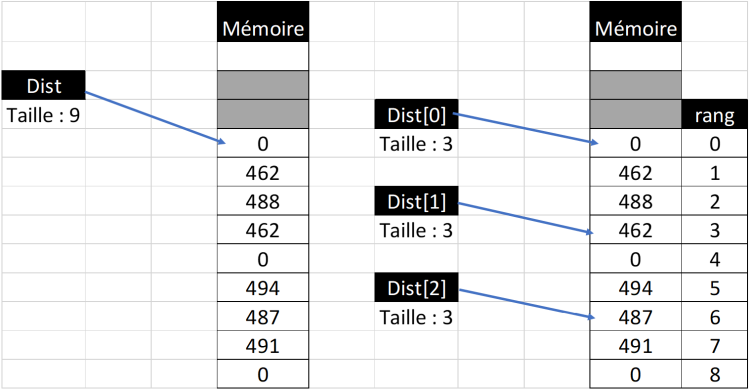
Comme nous l’avons déjà vu pour les caractères ou les nombres réels, l’ordinateur ne sait pas ce qu’est un tableau à deux dimensions. Néanmoins, les langages de programmation vont pouvoir à l’aide de quelques astuces simuler ce genre de tableau.
Tableau homogène avec Python et Numpy
Attention :
Pour représenter un tableau en Python, nous utilisons communément le type liste. Attention, une liste Python n’est pas un tableau au sens où nous l’avons décrit dans ce cours. C’est une structure de données qui va bien plus loin.
Sur le plan des similitudes, une liste Python est un ensemble de valeurs manipulées au travers d’une seule variable. Nous pouvons accéder à un élément particulier avec l’aide des [] et même modifier un élément particulier. Cependant, Python permet d’avoir des éléments de plusieurs types dans la même liste :
l = [3, 'banane', 5.5, True]
Cette manière de définir une liste est tout à fait valide en Python. La liste l contient 4 éléments, un entier 3, une chaîne de caractères 'banane', un réel 5.5 et un booléen True. Un tableau tel que nous l’avons décrit est défini par le type d’éléments qu’il contient. On ne peut donc pas mettre des éléments de plusieurs types dans le même tableau.
Remarque :
On pourrait être tenté de croire qu’une liste est donc un tableau, en mieux. Une liste vous permet de stocker n’importe quoi sans avoir à contrôler le contenu systématiquement. Python ne provoquera aucune erreur si vous ajoutez une chaîne de caractères dans une liste qui ne contient que des entiers. Cependant, le développeur devra être vigilant sur le contenu des listes et des instructions qu’il désire y appliquer.
Reprenons la liste définie au-dessus : l = [3, 'banane', 5.5, True]
Exemple :
Que va-t-il se passer si je décide d’ajouter 3 à chaque élément de la liste ? Pas de problème pour le premier puisqu’il s’agit d’un numérique. Cependant, Python va provoquer une erreur lorsqu’il va se rendre compte que je lui demande d’ajouter 3 à une ‘banane’. Cette souplesse que propose Python peut donc également être source d’erreur si le développeur n’est pas vigilant.
Remarque :
Le fait que les données ne soient pas du même type dans une liste va aussi nous faire perdre du temps en contrôle. À chaque opération que nous voudrons faire sur la liste, Python sera obligé de vérifier qu’elle se prête bien au contenu de la liste. Si je veux la moyenne de la liste l, il y a de fortes chances pour que Python s’insurge une fois de plus.
Mais du coup, est-ce qu’il est possible de représenter vraiment un tableau en Python ? Oui, mais pas dans la version de base de Python, il faudra passer par une bibliothèque qui s’appelle Numpy. En effet, Numpy est une bibliothèque Python qui permet de représenter des tableaux et des matrices (tableaux à 2 dimensions) et constitue la base de nombreux modules de calcul scientifique pour Python. Les tableaux Numpy perdent l’aspect hétérogène des listes Python mais gagnent en vitesse de calcul. Les tableaux Numpy ne contenant qu’un seul type de données, il n’est plus nécessaire de faire autant de vérifications que pour les listes, et les traitements se passent donc plus vite.
Exemple :
Si je crée un tableau Numpy à partir de la liste l ci-dessus :

Vous voyez que Numpy a tenté de trouver le type qui permettait de représenter toutes les valeurs et il a choisi de tout convertir en chaînes de caractères. Ce n’est pas forcément la meilleure chose pour faire des calculs mais il n’a pas eu le choix.
Complément :
Numpy, comme la plupart des bibliothèques Python est un projet OpenSource. Vous aurez plus d’informations sur le site officiel à l’adresse web Numpy.