Big Data : qu’est-ce que c’est ?
Contexte :
L’explosion des technologies de l’information et de la communication a coïncidé avec la production de données numériques en masse. Ces données se sont vite révélées être un véritable filon, dont l’exploitation est devenue stratégique. Cette situation a progressivement conduit à l’émergence du concept de « Big Data » qui a permis de cerner le potentiel de la donnée et d’en faire un élément incontournable dans les interactions interhumaines comme entre l’homme et la machine. Comprendre le Big Data, ses enjeux et ses différentes applications est nécessaire pour en saisir la portée.
Définition :
Les activités humaines sur Internet, les informations transmises et captées par les objets connectés, tout cela forme un tout : le Big Data. C’est un ensemble constitué d’une masse de données numériques provenant de plusieurs sources : les discussions sur différents médias en ligne (réseaux sociaux, messageries instantanées), les applications mobiles, les opérations e-commerces, les bases de données des industries et des entreprises. L’institut Gartner en donne une définition explicite en ces termes : « Le Big Data est une forte volumétrie, haute vélocité et grande variété de données qui exigent des techniques innovantes et rentables de traitement d’information pour une meilleure prise de décision. »
Bien qu’il soit difficile d’attribuer la paternité du terme Big Data à un individu en particulier, on reconnaît en John Mashey son principal vulgarisateur. Informaticien et chercheur à Silicon Graphics, il avait déjà esquissé en 1987 les contours du Big Data. Aujourd’hui, le concept a évolué et s’est enrichi de nouveaux principes.
Si l’on évoque souvent la profusion des données pour parler du Big Data, ce seul élément ne suffit pas à le caractériser. Le Big Data existe surtout au travers de la règle des 3 V édictée par Gartner. Les 3 V renvoient au volume, à la vélocité et à la variété des données constitutives de Big Data :
Le Volume, c’est la masse ou la quantité des informations générées et dont la mesure s’exprime en différents ordres de mesures : pétaoctets, exaoctets, zettaoctets, yottaoctets ou en bronto-octets.
La Vélocité fait référence à la vitesse à laquelle les données sont créées, recueillies, diffusées et analysées.
La Variété, ce sont les propriétés que présentent les données, c’est-à-dire format, nature et structure. Elles peuvent être structurées (dates, numéros de téléphone, numéros de cartes de crédit, adresses), semi-structurées (données produites en continu, données XML, journaux ou logs des serveurs) ou non structurées (images, fichiers audio et vidéo, emails, textes, commentaires sur les réseaux sociaux).
Désormais, deux autres V viennent s’ajouter aux 3 V principaux, ce qui étend la liste à 5 V. Il s’agit notamment de la valeur et de la véracité des données. Par valeur, on entend ce que l’on peut tirer de la donnée en termes de connaissance et de profit. Quant à la véracité, elle détermine le crédit qu’on peut accorder aux sources à l’origine des données.

Les 5 V du Big data |
|---|
Twitter exprime assez bien le principe de vélocité introduit un peu plus haut. On peut l’apprécier à la lumière de ces statistiques fournies par le site Planétoscope :
« Chaque seconde, environ 5 900 tweets sont expédiés sur le site de microblogging Twitter. Cela représente 504 millions de tweets par jour ou 184 milliards de tweets par an. Cette masse d’information vient alimenter le flot d’informations (Big Data) publié par l’humanité chaque jour sur Internet. »
Pour se faire une idée du volume des mégadonnées, il suffit de s’intéresser à d’autres statistiques (findstack) : « D’ici 2025, les experts indiquent que plus de 463 exaoctets de données seront créés chaque jour. ». À titre de rappel, selon l’ordre de mesure de stockage des données, 1 Exaoctet (Eo) = 1 024 Pétaoctets (Po), dont l’unité (1 Po) équivaut à 1 024 Téraoctets (To). Ce comparatif permet de se représenter la gigantesque masse de données qui pourra être produite sur une base quotidienne.
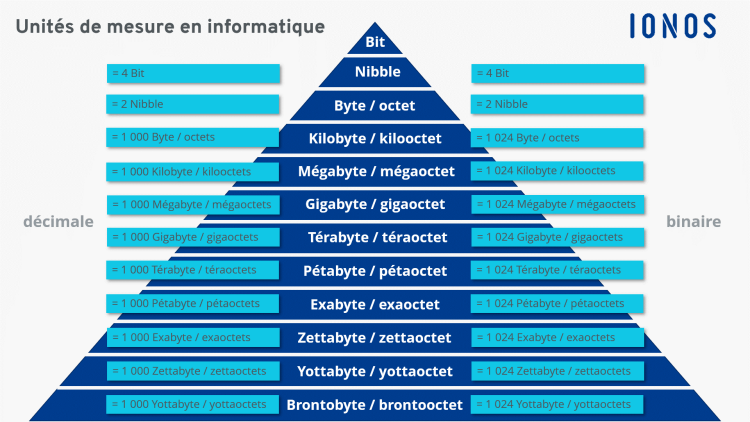
Aperçu des unités de mesure en informatique |
|---|
Les enjeux du Big Data
Aujourd’hui, on ne fait plus grand cas de l’accès à la donnée. On s’inquiète davantage de qui l’exploite, comment et à quelles fins. Pour les entreprises, il importe de développer une stratégie Big Data à même de répondre aux problématiques de la satisfaction client, de la productivité et de l’innovation. On tend ainsi vers des enjeux sur trois points principaux : technologie, organisation et économie. Le défi, c’est de réussir à concilier la bonne technologie et la bonne organisation pour des performances économiques optimales.
Big Data, quels enjeux technologiques pour les entreprises ?
Le Big Data reste un défi de taille à relever pour l’entreprise et sa DSI (Direction des Services Informatiques). On entre ici dans le cadre de la Business Intelligence ou informatique décisionnelle. Se doter d’outils capables de traiter des données massives en temps réel et de fournir des analyses prédictives devient impératif. Le premier problème qui se pose est celui du stockage. Au regard de la quantité de données à gérer, les data centers apparaissent clairement comme les supports de stockage privilégiés. Diverses technologies permettent de répondre à la problématique de stockage de données volumineuses. Dans le domaine du traitement du Big Data, Hadoop est sans nul doute la référence. Plusieurs plateformes se sont basées sur son architecture pour tirer profit de sa capacité à prendre en charge de grandes quantités de données (de l’ordre de plusieurs pétaoctets).
Hadoop, c’est quoi ? « C’est un framework libre et Open Source écrit en langage Java dont le but est de faciliter la création d’applications distribuées et scalables. Hadoop est donc conçu pour réaliser des traitements sur des volumes de données importants, de l’ordre de plusieurs pétaoctets. » (Source : Saagie).
Il comporte plusieurs modules :
Un système en charge des fichiers distribués, appelé HDFS (Hadoop Distributed File System),
Map Reduce pour le traitement distribué des données,
Un système dédié à la gestion des ressources du cluster (serveurs en réseau), Yarn (acronyme de Yet Another Resource Negotiator).
Dans un environnement distribué, le cluster Hadoop permet de conserver les données même quand les autres nœuds présentent des défaillances. L’architecture de Hadoop permet d’étendre le traitement des données structurées et non structurées sur plusieurs nœuds, ce qui augmente considérablement leur disponibilité, y compris en cas de panne. En dehors des solutions basées sur Hadoop, les entreprises peuvent aussi opter pour le cloud computing et sur les bases de données relationnelles SQL et non relationnelles NoSQL. Chacune de ces solutions a ses avantages, mais aussi ses inconvénients.
Complément :
Hadoop
Points forts :
Prise en charge des calculs simultanés ou parallèles,
Libre d’accès (open source),
Haute disponibilité des données, même en cas de défaillances techniques,
Manipulation possible de grandes quantités de données,
Rapidité de traitement des donnée.
Points faibles :
Limité dans les calculs en temps réel,
Difficile à prendre en main.
Cloud computing
Points forts :
Optimisation de l’utilisation des ressources,
Maintenance informatique simplifiée,
Dématérialisation du parc informatique.
Point faible :
Vulnérabilité des données aux cybermenaces.
L’adoption des systèmes de gestion de bases de données pose aussi le problème de leur compatibilité avec les solutions déjà présentes. Dans ce cas précis, le service informatique est tenu de veiller à l’interopérabilité entre les différents systèmes. La fiabilité des données collectées doit aussi être questionnée afin de réduire le taux d’erreurs au maximum. Prendre cette précaution est nécessaire pour ne pas fausser le processus décisionnel. Côté sécurité, la gestion des autorisations (accès aux outils Big Data) est essentielle.
Les enjeux organisationnels du Big Data
Le Big Data semble offrir les mêmes chances aux entreprises étant donné la facilité d’accès aux données. Mais la surabondance de l’information s’est peu à peu muée en une problématique que peu d’entités arrivent finalement à résoudre : l’identification de la donnée utile pour en faire un argument différenciant. Même si la quantité des données disponibles reste phénoménale, celles ayant de la valeur sont plutôt minoritaires et sont difficilement décelables. Pour isoler le bon substrat, il faut déployer des ressources matérielles et humaines suffisamment qualifiées. La mise en place d’un système de classification est donc nécessaire pour hiérarchiser les données.
Cela induit une stratégie de gouvernance des données dont la direction doit être confiée à un spécialiste de la donnée, idéalement un data scientist. Son profil est celui d’un professionnel avec des connaissances en statistiques, en data management et en informatique, qui sait évaluer les données dont il dispose. Il a un rôle de conseil auprès de la direction des systèmes d’information pour laquelle il produit des rapports qui peuvent influencer les décisions managériales.
Le data scientist occupe une place centrale dans l’entreprise. Il interagit avec les pôles commerciaux, financiers et marketing. En plus de la collecte et de l’analyse des données, il a la capacité d’identifier en amont les solutions de stockage et les outils d’analyse les plus pertinents. Il a aussi pour mission de développer des modèles prédictifs et des tableaux de bord qui facilitent la lecture de ses évaluations. Pour l’acquisition des compétences en sciences des données, l’entreprise peut choisir de former des ressources en interne ou opter pour le recrutement d’un nouveau profil.
Complément :
Au-delà de la nécessité de confier la stratégie de gouvernance des données à un spécialiste, le principal enjeu reste celui de la conduite du changement, étant donné que le Big Data contribue à la transformation de l’entreprise. Une synthèse du Cigref parue en 2013 le précise assez bien : « Le Big Data est une composante de la transformation de l’entreprise, il est transversal et touche tous les métiers. En ce sens, le Big Data n’est pas un projet SI : c’est une manière nouvelle de penser et d’appréhender l’information. Il s’agit donc davantage d’une (r) évolution culturelle et technologique que d’un nouveau sujet SI. »
Pour implémenter durablement une « transformation data », l’analyse de la donnée ne doit pas peser uniquement sur la DSI. Elle doit concerner tous les métiers de l’organisation. Cette approche permet aux différents services de mettre à profit leurs connaissances du terrain et des clients pour identifier plus rapidement les données ayant de la valeur. Dans cette optique, une formation des équipes à l’extraction et à la manipulation des données s’impose.
Big Data, les enjeux économiques pour l’entreprise
Porteur d’innovation, le Big Data sert les ambitions économiques de l’entreprise, à condition que des ressources humaines et technologiques soient disponibles. L’amélioration des résultats financiers passe par de meilleurs produits et des services de qualité, ce qui nécessite une juste exploitation de la donnée. Précisons que la conception et le déploiement de l’architecture du Big Data en entreprise ont un coût. Il y a par conséquent une notion de retour sur investissement à prendre en compte. Les bénéfices du Big Data peuvent s’apprécier sur plusieurs fonctions, à savoir le marketing, la logistique, les finances et les ressources humaines.
Comment ça se passe ? Pour un service marketing, l’accès à des données pertinentes est une véritable aubaine, puisqu’il ouvre la voie à une amélioration des services de l’entreprise. Avec le Big Data, les stratégies de marketing gagnent en efficacité grâce à un ciblage plus précis. On passe ainsi du marketing de masse à un marketing plus humain et personnalisé. Les comportements et les habitudes du client étant désormais connus, notamment par le truchement des données issues des réseaux sociaux, il est plus aisé de lui proposer des produits ou des services dont il a envie. Pour aboutir à des résultats probants et durables, le recours à l’intelligence artificielle est indispensable.
L’apport de cette technologie permet de produire une procédure d’analyse complète, c’est-à-dire descriptive, prédictive et enfin prescriptive. Sur un plan purement stratégique, en plus d’une meilleure connaissance du client, le Big Data donne les moyens d’affiner l’analyse concurrentielle. Cela aide à la préparation de campagnes marketing plus performantes. En plus, la donnée offre l’occasion d’analyser plus finement la satisfaction des clients dans le but de déceler les indicateurs pouvant servir à la fidélisation et à l’amélioration des services à la clientèle.
Associer le Big Data à la logistique permet d’optimiser plusieurs composantes de la chaîne logistique, comme la gestion des stocks, le réapprovisionnement et la gestion de la livraison. En équipant, par exemple, ses véhicules de capteurs, une entreprise de transport peut, à partir des données récoltées, identifier les facteurs qui influencent le plus la consommation de carburant. En recoupant les informations analysées, elle a la possibilité de créer des itinéraires pensés pour réduire le temps de trajet et écourter les délais de livraison.
Quand il est appliqué aux ressources humaines, le Big Data se révèle être un formidable outil qui peut notamment être mis au service du recrutement. Pour un DRH en quête d’un profil particulier, l’intuition comme seule arme ne suffit pas. La donnée suggère une approche plus scientifique, basée sur des statistiques et des faits. Ainsi, avec un algorithme nourri au Big Data, le processus de recrutement peut être non seulement accéléré, mais aussi amélioré. La data contribue par ailleurs au renforcement de la marque employeur, un critère déterminant dans la gestion des talents, qu’il s’agisse de les attirer ou de les fidéliser.
Les innovations liées au Big Data
Avec le Big Data sont apparues des problématiques dont la résolution dépend de la capacité des organisations à innover. Considérée littéralement comme une matière première, la data se révèle être un véritable accélérateur de progrès dans plusieurs domaines, notamment celui de la data science (science des données) et de l’Intelligence Artificielle (IA).
Définition : La data science, qu’est-ce que c’est ?
La data science, ou science des données, est la combinaison de « plusieurs domaines, dont les statistiques, les méthodes scientifiques, l’Intelligence Artificielle (IA) et l’analyse des données, pour extraire de la valeur des données » (Oracle). La data science fait référence à l’ensemble de la procédure menant à la valorisation de la donnée : analyse, manipulation, agrégation et nettoyage. Pratiquée par les data scientists, elle est indispensable à la mise en place de toute stratégie Big Data.
La science des données est étroitement liée au Big Data, même si la data science peut s’appliquer à de faibles volumes de données. Toutefois, la discipline a connu un essor considérable du fait de la croissance exponentielle des données produites par l’homme. L’irruption des nouvelles technologies englobant les objets connectés et l’utilisation massive des réseaux sociaux, des moteurs de recherche et des applications mobiles suggèrent une augmentation de la data.
Mais la donnée n’a de sens que si elle est exploitable, et c’est là tout l’intérêt de la data science. En sondant différents « lacs de données » (data lakes), les data scientists cherchent à identifier des tendances, des points de connexion et d’intérêt afin de générer des modèles à l’intention de ceux qui ont le pouvoir de décision dans l’entreprise.
L’exploitation de la donnée se fait en plusieurs étapes :
La collecte
L’entreposage dans des centres de données
La classification
L’analyse
Le reporting
En tant que technologie, la science des données se présente comme une composante majeure des outils d’aide à la décision, de prédiction et d’automatisation de tâches. On la retrouve également dans les technologies de reconnaissance textuelle, vocale ou faciale. Les domaines d’usage de cette science sont légion et ne cessent de s’élargir.
Complément :
Pour des prédictions météorologiques, la data science peut être mise à contribution pour analyser des données fournies par plusieurs sources : satellites, bateaux, radars, avions. À partir de cette analyse, on établit des modèles pour prévoir le temps sur un intervalle donné, mais aussi anticiper la survenue de certains aléas climatiques.
Autre exemple parlant : celui de la data science appliquée au commerce du détail. Pour améliorer leur moteur de recommandation, les plateformes e-commerce scrutent l’historique des achats des utilisateurs, la liste des articles figurant dans leur wishlist ou dans leur panier. Sont aussi pris en compte les produits avec lesquels il a eu une quelconque interaction (commentaire, notation). En croisant ces données avec celles d’autres clients, le moteur de recommandation suggère différents produits au client.
Définition : L’intelligence artificielle, qu’est-ce que c’est ?
On définit l’Intelligence artificielle comme « des systèmes ou des machines qui imitent l’intelligence humaine pour effectuer des tâches et qui peuvent s’améliorer en fonction des informations collectées grâce à l’itération » (Oracle).
L’Intelligence artificielle peut évoluer par le truchement d’un processus d’apprentissage connu sous le terme de « Machine Learning » ou « Deep Learning ». Elle apprend en se « nourrissant » de données. Plus de données implique l’assimilation d’une grande quantité d’informations et une IA plus performante et autonome. L’IA a comme matière première le Big Data, d’où elle tire ses ressources. Si les débuts de l’IA ont été quelque peu balbutiants, en partie à cause de la méfiance suscitée par cette nouvelle technologie, aujourd’hui elle occupe une place de choix sur la carte technologique.
Même si une certaine retenue demeure du fait de sa capacité à prendre des décisions de façon autonome, son potentiel ne fait aucun doute. Big Data et IA sont complémentaires l’un de l’autre. Une IA qui a accès à des données massives gagne en intelligence et peut exploiter plus efficacement le Big Data pour une gestion des données optimisée. Il s’agit par conséquent de deux systèmes qui sont appelés à converger et à s’entremêler.
Une IA plus intelligente est utile aux outils de prise de décision, à l’automatisation des tâches, au diagnostic et à la résolution des problèmes. Portée par le Big Data, l’intelligence artificielle permet d’améliorer les connaissances déjà acquises et d’explorer de nouvelles pistes, et cela dans divers domaines. L’amélioration de l’IA se remarque notamment dans la conception de programmes dédiés à l’automatisation de la prise de décision ou dans le développement de logiciels d’analyse de données plus précis : des machines trouvent du sens à la donnée et accélèrent la prise de décision, des promesses peuvent être tenues avec une IA améliorée.